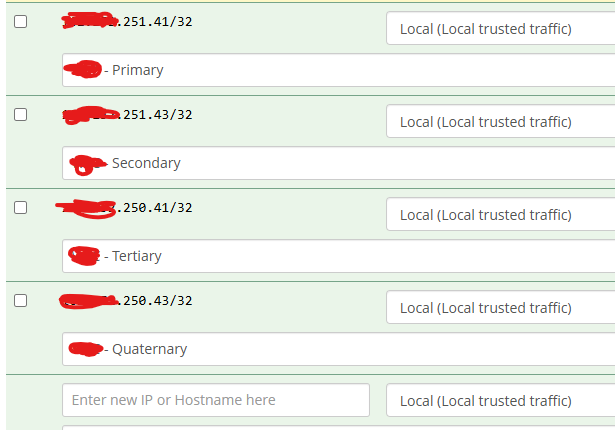
I have been Google-Fooing to no avail - This morning my carrier had a Datacenter go down, and we should have failed over cleanly to another center with the SRV records that we were registered to - but we didn’t. Looking at packet-traces and such, here is the list of centers in the SRV record:
First two IP’s are at the dead data center, next two are alive and kicking.
But here is the problem - PJSIP registers with the first available gateway xxx.xxx.250.230/32 but it insists on sending the Qualifty packets to the first (dead) server xxx.xxx.251.41/32 - so Incoming works, but outgoing fails.
Solution is to configure an outbound proxy in Advanced Settings - sip:xxx.xxx.250.230 and then it registers and qualify’s and Outbound proceeds.
Does anybody know when this will work properly - it totally kills the redundancy of the SIP trunk and causes an outage.
I’d suggest filing an Asterisk issue[1]. I found no existing issues reported for such a thing.
From a “how it works” perspective each SIP request results in resolving down the hostname to a list of resolved targets (IP addresses + ports + transport). Request goes out. It fails after a period of time (or instantly in the case of TCP/TLS). On failure of the request it has to invoke a bit of failover logic to move on to the next entry in the list. OPTIONS may not be invoking that logic. I don’t have a time frame on when it would get looked into and resolved.
Let’s see your SRV records for all these IPs. Just want to make sure the priority and weights of the records are correct for a failover setup.
I use SRV and I’m not having these problems. Then again, a REGISTER contact doesn’t have SRV in use anyways (unless an outbound proxy is set and using it)
Yes - Setting the OB Proxy to the working server (sip:xxx.xxx.xxx.xxx) makes it work fine but I found out the hard way this morning - when the primary servers come back online, then having it as the forced OB proxy breaks it again sometimes if the secondary servers change - which it did for 2 customers. I just had to pop on and remove it, but it did stop calls from going out until I did it.
It’s a work-around, but not a good one - Joshua gave me a link to the SIP spec that they program to and it specifically says that SIP should step through the list in the SRV record until it get’s a valid response on the Qualify - it’s just stopping after the first server on the list.
Weird bug, and it’s only a problem because the carrier’s Data Center went down forcing the fail-over - it worked for Inbound, just not Outbound.
This is my 5th carrier - True Seamless Fail-Over seems very elusive - no one in the past has been able to have it work correctly, but maybe this bug was the problem all along - I don’t know.
I would love to see a packet trace from a carrier that actually worked - I am thinking that because of this bug, they must do it differently - maybe regenerate the SRV record dynamically putting the (working) servers first on the list - That would bypass this bug.
And there you go - Because it is not Qualifying the Trunk, the PJSIP Bug with sending the Qualify to the wrong server (not the one it is registered to) never comes up - It works!