Look this example:
exten => s,1,Progress()
same => n,Set(audio=${SHELL(node /opt/aws-nodejs-sample/script.js --mp3=/home/asterisk/audio-${cpf}.mp3 --text=’${nome}’ --wav=/var/lib/asterisk/sounds/audio-${cpf})})
same => n,Playback(audio-${cpf})
Look this example:
exten => s,1,Progress()
same => n,Set(audio=${SHELL(node /opt/aws-nodejs-sample/script.js --mp3=/home/asterisk/audio-${cpf}.mp3 --text=’${nome}’ --wav=/var/lib/asterisk/sounds/audio-${cpf})})
same => n,Playback(audio-${cpf})
Vote here ![]()
I exactly followed theclevercrib’s “working summary” above and was able to get the script to generate .mp3 and .wav files when I call inbound and trigger a TTS event. They are generated properly and sound fine when I play them manually. Problem is there is no sound on the incoming phone line. When I use flite and call inbound there is sound.
Any ideas what I might be missing?
I’m running FreePBX 14.0.3.6 Sangoma distribution. Asterisk 13.
Change “ext” => “sln” to “ext” => “wav”
Thanks to everyone on this post. I have learned a lot! I have come up with a different approach and not reliant on the modules Text to Speech engine or Text to Speech application. Using the dialplan + PHP
You still need an Amazon account. And node.js
Kudos to @jersonjunior!
Sample project to demonstrate usage of the AWS SDK for Node.js:
cd /opt/
git clone https://github.com/awslabs/aws-nodejs-sample
cd aws-nodejs-sample
npm install
npm install optimist
npm install child_process
nano script.js
#!/usr/bin/env node
// Load the SDK
var argv = require('optimist').argv;
const AWS = require('aws-sdk')
const Fs = require('fs')
var child_process = require('child_process');
// Create an Polly client
const Polly = new AWS.Polly({
accessKeyId: "youraccessKeyIdgoeshere",
secretAccessKey: "yoursecretAccessKeygoeshere",
signatureVersion: 'v4',
region: 'us-east-1'
})
letparams = {
'Text': argv.text,
'OutputFormat': 'mp3',
'SampleRate': '8000',
'VoiceId': 'Joanna'
}
Polly.synthesizeSpeech(params, (err, data) => {
if (err) {
console.log(err.code)
} else if (data) {
if (data.AudioStream instanceof Buffer) {
Fs.writeFile(argv.mp3, data.AudioStream, function(err) {
if (err) {
return console.log(err)
}
console.log("The file was saved!")
var output = child_process.execSync('lame --decode ' + argv.mp3 + ' ' + '-b 8000' + ' ' + argv.wav + '.wav');
})
}
}
})
Press ctrl+x y enter to save and exit
nano /var/lib/asterisk/agi-bin/pollysimple.php
#!/usr/bin/php -q
<?php
// [polly-simple]
set_time_limit(30);
require('phpagi.php');
$agi = new AGI();
$agi->answer();
$text= "Hello, this is a test of Amazon Polly. Change this text to hear something different.";
$id= uniqid();
shell_exec("node /opt/aws-nodejs-sample/script.js --mp3=/tmp/polly-$id.mp3 --text='$text' --wav=/tmp/polly-$id");
$agi->stream_file("/tmp/polly-$id");
$mp3file = "/tmp/polly-$id.mp3";
unlink($mp3file) or die("Couldn't delete file"); //deletes mp3 file
$wavfile = "/tmp/polly-$id.wav";
unlink($wavfile) or die("Couldn't delete file"); //deletes wav file
exit();
?>
Press ctrl+x y enter to save and exit
Now we have to change permissions:
cd /var/lib/asterisk/agi-bin/
chown asterisk:asterisk pollysimple.php
chmod +x pollysimple.php
Now to put it all together:
Freepbx gui: Admin -> Config Edit -> extensions_custom.conf:
[from-internal-custom]
;internal extension of [polly-simple]
exten => 400,1,Goto(polly-simple,s,1)
;can be referenced by creating a Custom Destination
;Target= polly-simple,s,1
;Description= A simple Amazon Polly test
[polly-simple]
exten => s,1,Answer()
exten => s,n,AGI(/var/lib/asterisk/agi-bin/pollysimple.php)
exten => s,n,Hangup()
Click Save and Apply
Calling extension 400 will play the text in pollysimple.php if everything went ok.
The temp files are deleted.
Creating a Custom Destination is optional. Unless you want to use it in another application.
Good luck! Let me know if you come across any issues.
–Adam
Sorry I’m late to the party! Looks like this is right up my alley (and precisely what we’ve been looking for  ). Forking tts and ttsengines modules to add ‘polly’ engine where appropriate. I’ll also whip up a handy script to aid in the installation of the AWS node components and setting up the keys, region, voice, etc.
). Forking tts and ttsengines modules to add ‘polly’ engine where appropriate. I’ll also whip up a handy script to aid in the installation of the AWS node components and setting up the keys, region, voice, etc.
I should have something ready within a week. My preliminary tests using the helpful posts in this thread were flawless and I already have Polly speaking loud and clear on a lab system. I’ll post back here with a link to the install script as soon as we get code merged in for propolys-tts.agi proper.
UPDATE 2019-01-15: The Workaround at the bottom of this post is no longer necessary. The install-pollytts script will install the recently released updated tts and ttsengines modules from the FreePBX Edge Repo automatically. The following module versions provide the necessary Polly TTS support in the GUI:
tts v13.0.11
ttsengines v13.0.7.4
UPDATE 2019-01-10: I have altered the install-pollytts script to preserve existing keys, region, and voice selection from polly.js so you can run the script again to alter a single setting or to simply update the components without having to re-enter everything again (perfect for quickly changing Polly Voices). I have also updated polly.js to delete the extra .mp3 file after conversion to .wav to free up space. If you have already installed prior to 1/10/2019, simply download a fresh copy of the install-pollytts script and run it to update everything without losing existing config.
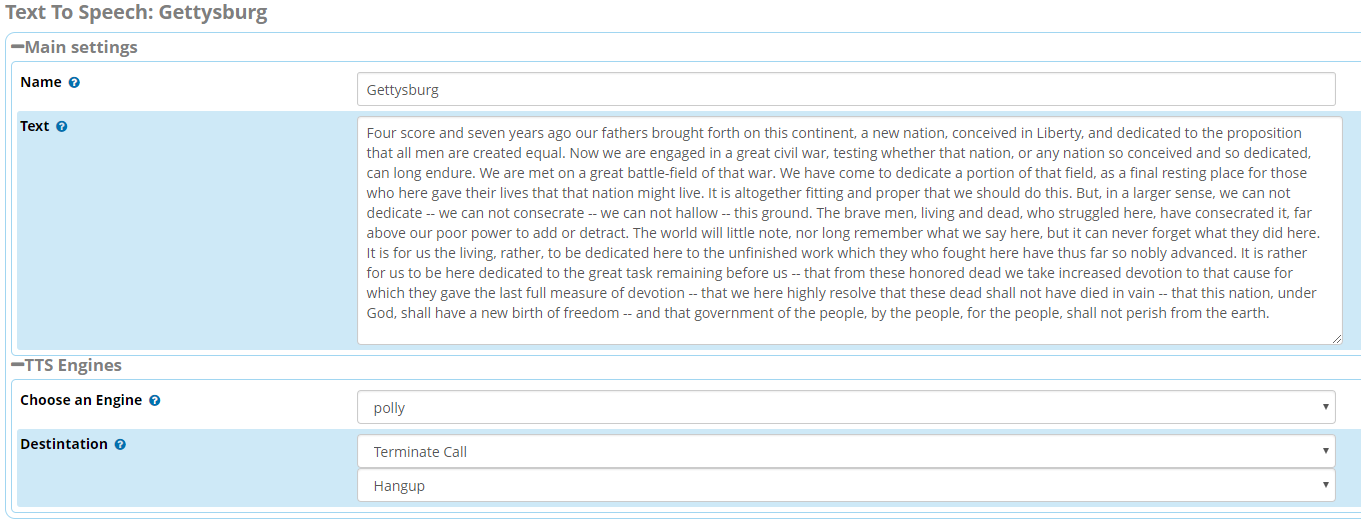
Well, that went way faster than I expected. Everything is ready and tested. I even placed the entire Gettysburg Address in a TTS element and it played back the entire speech PERFECTLY. All we need is the changes merged for the modules to add the ‘polly’ engine and we’re golden. I’m writing out these instructions now, but note that you won’t be able to use Polly until one of the following two conditions are met:
You make your own alteration to /var/www/html/admin/modules/tts/agi-bin/propolys-tts.agi to add the polly engine —Yes, I say the module copy since this will allow you to Apply Config without losing the edit every time. You can set Enable Module Signature Checking to No in Settings > Advanced Settings (temporarily, until the modules are officially updated) to get rid of the Security Warning— That said, there’s a “noob-friendly” workaround outlined below for performing this change
My changes are merged into the FreePBX tts\ttsengines modules by Sangoma and released as official updates, which will happen once they have had a chance to review and follow their normal procedure for these things (I’ll post back here when that happens)
Alright, folks, this is super simple. Access the server via SSH or local console and execute the following commands to download and run the installation script:
wget https://files.thewebmachine.net/install-pollytts.sh
chmod 755 ./install-pollytts.sh
./install-pollytts.sh
NOTE: If you are using AWS FreePBX from TheWebMachine Networks, simply execute this command to run the installation:
smartupgrade install-pollytts
Towards the end of the installation, you will be asked for the following information:
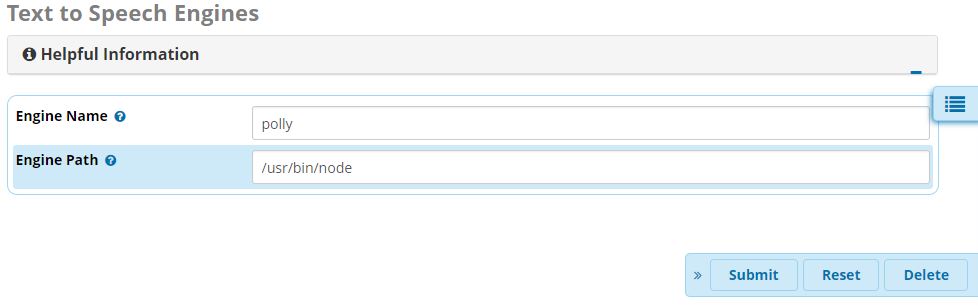
Once the script is finished, you’ll want to add the ‘polly’ engine via Settings > Text to Speech Engines and specify ‘/usr/bin/node’ as the Engine Path:
Please be advised of the following limitations when using the AWS Polly engine to create TTS elements:
You CANNOT use single quotes/apostrophe (') including contractions (use dont instead of don’t), double quotes ("), or carriage returns/newlines in your spoken text. Any of these (and possibly other special chars) will break the playback and you will get either only a partial audio file or no audio at all. Polly will automatically pronounce contractions without an apostrophe (like dont) correctly
AWS Polly has a 3000-character limit per API request. If you send more than this in a single TTS element, you will get no audio. If you need to provide spoken word longer than 3000-chars, simply break it down into multiple TTS elements and string them together in sequence within your dialplan (Part1 Destination → Part2; Part2 Destination → Part3, etc)
—WORKAROUND: BEFORE THE UPDATED TTS MODULE IS OFFICIALLY RELEASED—
Since the updates to tts and ttsengines modules are still pending review by Sangoma, you’ll need to add the engine manually in order to use it right now. I have decided to make this as painless as possible (no direct file edits). These steps will have you download a modified copy of propolys-tts.agi to replace within the tts module (the same code pending review in git). Simply run these commands via SSH or the local console:
cd /var/www/html/admin/modules/tts/agi-bin/
mv propolys-tts.agi propolys-tts.agi.bak
wget https://files.thewebmachine.net/propolys-tts.agi
chown asterisk:asterisk propolys-tts.agi
chmod 755 propolys-tts.agi
After you have made this change, you will start seeing a Security Warning appear at the top of the GUI. You can turn this off in Settings > Advanced Settings and set Enable Module Signature Checking to No. Once the official tts module has been updated, you should go back and turn Enable Module Signature Checking to Yes, as this helps to protect your server.
—END OF WORKAROUND—
That’s it! Now you may create new TTS elements in Applications > Text to Speech and select ‘polly’ as the engine to use.
FINAL NOTES ABOUT AWS POLLY: AWS gives customers 5 million characters per month for free for the first 12 months, starting from your first request. You pay for usage beyond that ($4 per million chars). The way the TTS module is currently written, your TTS audio files are preserved in /var/lib/asterisk/sounds/tts/ after the first time they are encoded. So long as that TTS element text field remains unchanged and you don’t change Polly Voices, no additional requests will be made to Polly for that TTS element. AWS Polly Pricing: Amazon Polly Pricing
Whatever you not adding the needed settings I’m the GUI. They should not have to use a script from CLI to add the fields to setup Amazon TTS.
Secondly if characters create issues why not sanarize them out before you send it to Amazon.
The fields (access key, secret key, etc) are currently within the polly.js file (which is literally the same code posted at the beginning of this topic). One is welcome to edit the /opt/aws-nodejs/polly.js file manually if they want. I included it in the script in order to keep with being “noob-friendly.” With the way the TTS module is currently written, it’s simply not sensible to try to include the fields via GUI. This is something that can be tackled within the Polly TTS “module” that I plan to include in the rewrite for v15. Besides, every TTS engine currently supported by the module (spare the default flite) requires some sort of backend config…full-blown Cepstral requires a license to be added via CLI, for example.
Sanitization is also something that can be more reasonably handled during the “modularization” of the TTS module. As it stands right now, neither the TTS module nor any of the TTS engines do a very good job of sanitizing what is provided in the GUI. Even flite can be tripped up fairly easily. The issue isn’t within polly.js…by the time the TTS text makes it there, it’s already screwed. Sanitization would have to be handled by the module when the user enters it - before it is ever presented to propolys-tts.agi, as this is where it gets tripped up (variable expansion in AGI).
I never understood or understand why anyone wants to use this module. Is there something I’m missing?
Why someone would want to use Text to Speech? I’ve found that when a company gets large enough, establishing a single consistent “voice” to record (and re-record) all of your prompts, announcements, etc - especially if emergency or last minute, can prove difficult unless you pay a company to record for you every time you need something changed. No one wants a smattering of different voices being played to their customers as they traverse the dialplan. Consistency is key. There are many cases where TTS can be helpful and MY hope is that we can open up TTS into other areas of FreePBX/Asterisk, such as IVR/queue announcements pointing to a TTS element instead of a static sound. (While a minority, I know I’m not the only person to suggest this over the years.)
Now, I could understand if this were still, say, pre-2010 or even pre-2015…when TTS synthesis was still pretty awful. However, nowadays, TTS is used literally everywhere. Call your bank. That “lady” asking for your account # is likely computer generated. Hell, Amazon wouldn’t have put so much work into Polly (which powers the voice of Alexa) if it wasn’t worth it. As I said, I agree that the majority of engines based on old school mechanics still mostly suck. However, Polly is worlds apart and is the most natural sounding TTS I’ve ever heard (Sorry, Google!).
Seriously, check out this wav file and hear for yourself. I pulled it from a test system after listening to the Gettysburg Address on my softphone. https://files.thewebmachine.net/polly-tts-6e2a369167f3f1e574bfbb738566ba78.wav
I’m not saying that. I just did a presentation at Astricon this year that utilized FreePBX, TTS, ASR and Amazon Lex. The question I have about the module is that it’s static. It doesn’t support variables in the text (it should) and therefore it’s very limited in scope besides wanting to have a consistent voice.

Demo here:

Again my question was more towards the static nature of the TTS module itself. Additionally Tony is right that these settings should be in the module but that won’t stop us from merging your changes. This module just needs to go to the next ‘level’
Ah, I missed that Astricon presentation! I know what I’M doing for the next 30+ minutes. haha
I get what you mean now and I entirely agree, the TTS module as it stands is woefully outdated and in need of a total rewrite. I’ve been looking at what you’ve laid out so far in v15 and I think it’s a good start. Once both tts and ttsengines are modular in nature**, we can start building out more dynamic elements and really rock some TTS goodness. That said, in the meantime, patching this old beast will have to suffice. {shrugs}
** (I really think these two modules should be combined into a single TTS core module, to simplify the “sub-module” architecture that will plug into it. Vis-a-vis: I had to fork both tts and ttsengines in order to add Polly; I shouldn’t have to write two “sub-modules,” one for tts and one for ttsengines, in the future. Does that make any sense?)
The module is very lacking, but having something like the module with enchantments would be a huge boon. This is very often a contention point for us. FreePBX would be a much easier sell if it were easy to deploy consistent (volume, speed, tone) from the GUI, but since we only have Flite, FreePBX solutions often come up short. I know there are ways to “Fix” this, but based on my experience, this would be easy to sell as a commercial module. Adding the ability to add variables would be great, but just getting to the GUI would be a big boon to start with.
We did that before. It was called Grammar, AKA “Magic Button”. TTS Engines was originally commercial. It did not sell as well as you think
I think a key differentiator is the rise of these very decent TTS programs, like Polly, who have gotten demonstrably better with each passing year. With the exception of one time, people that have listened to the Polly demo, often surprised, acknowledge its adequacy.
When quoting a system in the beginning of the engagement, offering a solution that avoids the extra steps of getting a viable recording (background, tone, volume, etc) is something that is easy to justify. Granted there is a balance of perceived value and pricing that has to be figured out, but the sheer popularity of this thread is proof enough of the pent up demand.
The other issue with TTS being commercial is the fact that you still become dependant on someone else’s TTS engine, licensing, potential royalties/module revenue sharing, etc. As has been touched upon in this thread, a rewrite of TTS is in the works for FreePBX v15 that will bring much of what you speak of, @comtech. There will almost always be some sort of backend installation necessary (even if it’s just a yum package) for anything beyond flite unless an engine’s license allows for Sangoma to use it “pre-installed” in FreePBX without creating extra legal mess or financial steps in the process. Tho, the new System Updates components in FreePBX could handle a simple package install. Even still, there could be licensing issues with some engines just going that far with it.
All that said, the TTS module is fine staying OSS. It’s just been neglected for years, which is the only real oversight here…but modernizing it is very much on the to-do list now.
Are you doing that?
I was referring to the modularization of TTS that you’ve already started on…and that I intend on contributing heavily to. So, I guess the answer to your question is, “sorta?” lol This will allow us to build out option fields in the GUI specific to each engine and tackle backend setup tasks by way of each engine’s module. Am I missing something?
I’m not doing any work on TTS in the short or long term so just seeing what you meant.