So this question is probably better suited for the Asterisk community but I figured I’d start here since I am not really active at all over there. I’ll dip my toes over there if nobody here has done this work.
We have recently started moving some of our on-prem FreePBX deployments to AWS EC2 and have been surprised by the bandwidth usage for the deployments, especially with environments that have 20+ phones in the environment.
This bandwidth usage is purely when the systems are idle and seems to be just SIP traffic between the endpoints (which are physical phones) and the SIP system. Here is an example for an instance with around 50 phones.
The flat line is after hours when the office is closed and phones aren’t really being used. That spike at midnight is I think when the system downloaded some updates.
We’ve never really noticed before with our on-prem deployments, mostly because we’ve never needed to monitor bandwidth usage, but now with the Amazon hosted instances it’s become pretty obvious that it seems like there is a lot of traffic that’s used between a phone and the PBX even when sitting idle.
In this particular environment we have SIP over TCP enabled, however I am not sure that SIP over UDP would consume that much less bandwidth.
Has anyone analyzed bandwidth usage on their own systems and can confirm that I don’t have something miss configured and that phones sitting idle do in fact consume that much bandwidth by design?
Good thought. This particular deployment is SIP only to physical phones on desks and the SIP trunk for inbound/outbound calls. Nobody at this deployment is using UCP or any HTTP portals for that matter. Any other service is blocked at the firewall.
I should have also mentioned that we’ve compared bandwidth usage with some of our on-prem deployments after noticing this on the hosted instance and they seem to match up between deployments of similar sizes, we just never noticed before because it didn’t really matter for on-prem installations since the phones are always local to the PBX.
So the options are:
That’s really how much bandwidth is needed in a SIP environment even when the phones are sitting there idle.
We have something configured that aggressively uses bandwidth that didn’t really matter for on-prem deployments but that can be adjusted to reduce bandwidth usage between phones and the pbx.
If it’s #1 then c’est la vie I guess, but if it’s #2 I would love to learn what we were doing “wrong” and adjust.
I took a quick screenshot of the network graph from our FreePBX instance on our VMWare host. We are using around 90 physical phones at this location. Everything is now on idle except the peak on the right is just one phone call. It looks like our bandwidth is much lower compared to yours.
30Mgs seems a lot for 20 extensions, which is why I suggested looking more analytically at the traffic, expect about 200kbs per active call and a few b’s for SIP registrations and options and notify’s in standbay
Are you sure this isn’t blocked toll fraud attempts, and other attacks on the system?
SIP doesn’t need any bandwidth when idle. However, it is usual to use registration (with a finite expiry time) for at least some endpoints, and all FreePBX extensions, and also it is common to test connectivity with OPTIONS.
The system, may also be doing NTP requests, although these may be up to about 20 minutes apart.
I’m not sure if Asterisk re-verifies DNS in the background, or waits until the next time it is needed.
I guess I can’t be 100% sure until I’ve actually looked at the pcap traffic and determined what it is but I would be really surprised if it turned out to be something malicious. I think we just have something configured on these phones that’s pretty bandwidth intensive and I just need to figure out what it is. I’ll reach out with additional questions once I’ve had a chance to take a look at things a bit closer.
The average SIP packet is about 600 bytes. The chart that you’ve shown looks to be overall usage (TX/RX) for the traffic on the server. So if we break it down:
Phone Sends REGISTER → 600 bytes out phone / in for pbx
PBX sends 401 Unauthorized → 600 bytes in phone / out pbx
Phone Sends REGISTER (with extra headers) → 600 bytes-ish out phone / in for pbx
PBX sends 200 OK for success → 600 byes in / out
In that process alone the phone has sent 1200 bytes out and received 1200 bytes in or 2400 bytes of bandwidth. How often is a phone registering? Times that by 50.
Doing a SUBSCRIBE for BLF or MWI, same thing. Gonna be about 2400 bytes just to authenticate. Now at that point the PBX will be sending NOTIFY messages (600 bytes-ish) to the phone and the phone will send back a 200 OK to ACK that NOTIFY. If the phone is doing multiple BLFs, this process is repeated for each BLF subscription.
Are the phones programmed to do Keep-Alives? If so, the phone will send out an OPTIONS at the proper interval. The PBX will send back a 200 OK for the ACK. Conversely, the PBX is going to qualify aka keep-alive all the endpoints. Same process just opposite direction. How often is the qualifying happening?
So idle aka not talking doesn’t mean the phone’s network traffic is also idle. REGISTER, SUBSCRIBE, NOTIFY, OPTIONs are still happening. Each of those interactions is about 1200 - 2400 bytes of TX/RX combined bandwidth. The shorter the intervals for each of those, the more it happens and thus the more bandwidth it generates.
Now when a call is happening, then it is even more. BLF’s for call pickup, etc will generate NOTIFY messages (and ACKs). The RTP alone is going to jack that up because 80Kbps still means about 3,000 packets are transferred every 60 seconds in a call. RTP packets are close to 1500 bytes per packet with the headers/overhead.
So in an office setup the receptionist phone that has a side car and 30 BLFs is going to generate more bandwidth usage than the co-workers phone that just has a single line and MWI subscriptions happening. Even on days they are closed and zero calls hit the phones.
Oh and that bandwidth chart isn’t just for SIP, right. Without having an idea of what else is running on the system, what else it is doing (backups, etc) it’s hard to say what is causing that bandwidth (looks more like transfer) usage. Unlike Chan_SIP, Chan_PJSIP doesn’t just do a DNS lookup at start or reload. It does a DNS lookup for every request, if any types of domains are being used in configs that will be another thing happening. But there can be a lot going on that system, in the background or otherwise, not related to SIP.
For a point of reference, my system (just Asterisk) with roughly 3K endpoints yesterday did roughly 14GB of outbound data transfer but the actual speeds used ranged from 1.3Mbps to 2.2Mbps (peak).
@BlazeStudios thank you for this breakdown. Just to be clear, I did use “idle” as a shorthand for “excluding voice traffic or not being used for a call”. I am aware that there is a bunch of stuff that happens between the phones and the PBX with them just sitting there and you’ve broken down a lot of them very nicely here.
The graph is total bytes out from the system over a day and includes all traffic, not just SIP. I chose to mention just SIP in my original post given that that’s the primary function of the system and SHOULD be the bulk of the traffic.
I think it’s a combination of BLF subscriptions and keep alive settings (ie. we have the various Keep Alive settings set to 60 seconds, both on the SIP settings at the system side and on the phones themselves) and the number of phones (in this case around 50) that are causing this and I just need to confirm that and figure out if there is a combination of settings that would reduce this traffic and still provide the same experience as what’s in place currently.
The only thing you can really do is extend the interval times for registration, keep-alives and subscriptions. That will reduce how much data is being transferred as less requests will be made.
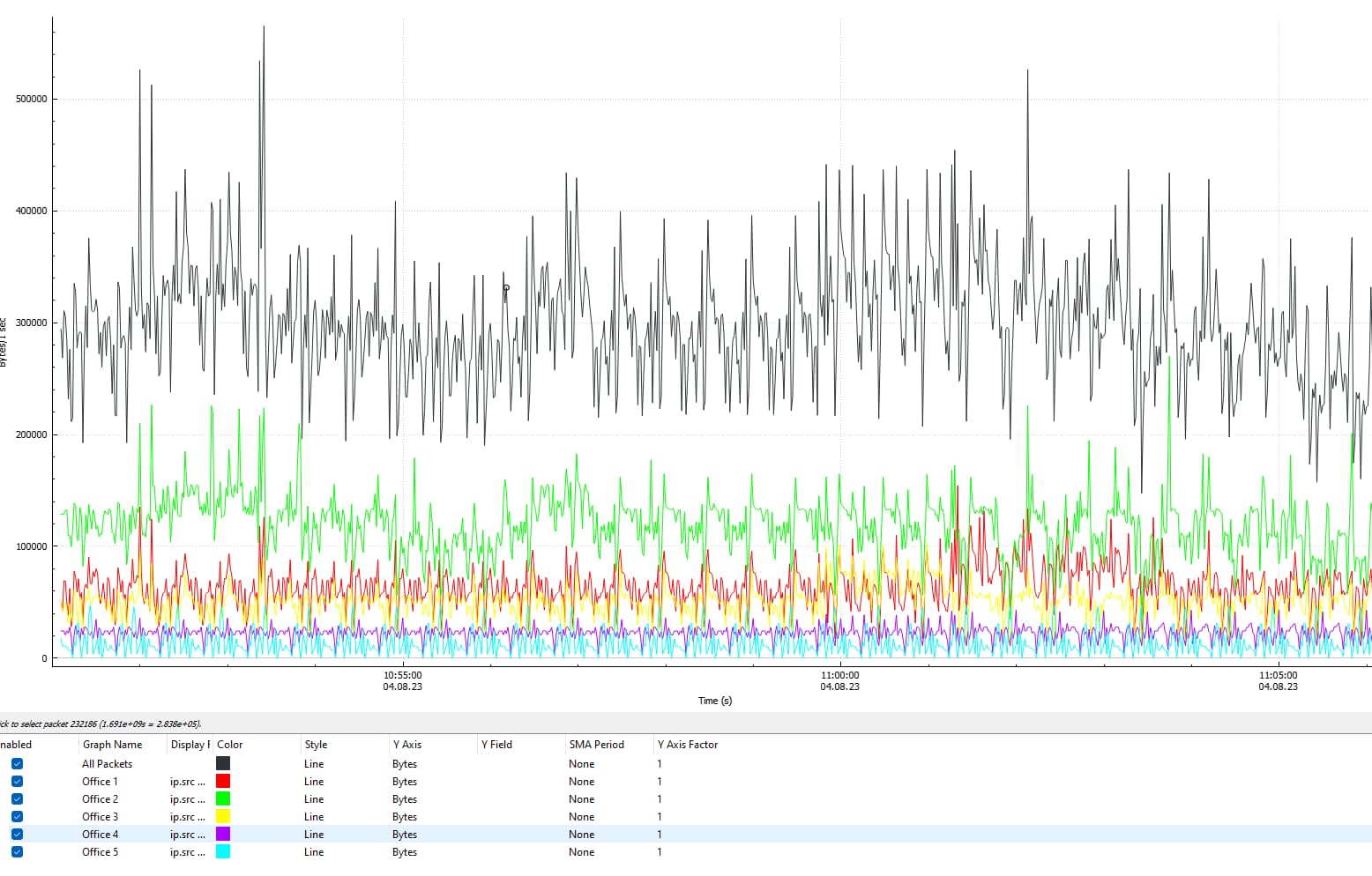
Quick sanity check confirms that it’s the phones using that bandwidth. Captured about 15 minutes of all network traffic from the hosted instance to a PCAP file (which grew to about 267 MB) and opened it up inside of the I/O Graphs on Wireshark.
Then compared the graph for total Bytes used for all packets to packets separated out by office location for this particular deployment (total of 5) where I know for a fact that the only ports that are accessible from these locations are SIP over TCP and RTP. For this particular graph I’ve filtered out all RTP packets.
Now on to figuring out how to break down what type of traffic is the heaviest user to see if settings can be adjusted to reduce that usage.
That setting only impacts TCP/TLS based transports. If that is what you are doing, you’re fine. However, if you are using UDP transports then the qualify_frequency for the individual endpoints/aors is used.
Well then the numbers I gave need to be adjusted to be a bit higher as TCP is a bigger payload thus the packet size increases. Plus TCP is an ongoing connection, not really sure how much that adds to it all as there more being done like handshakes vs fire and forget.