残念ながら回答や情報を得られなかったため、自身で調べて解決をいたしました。
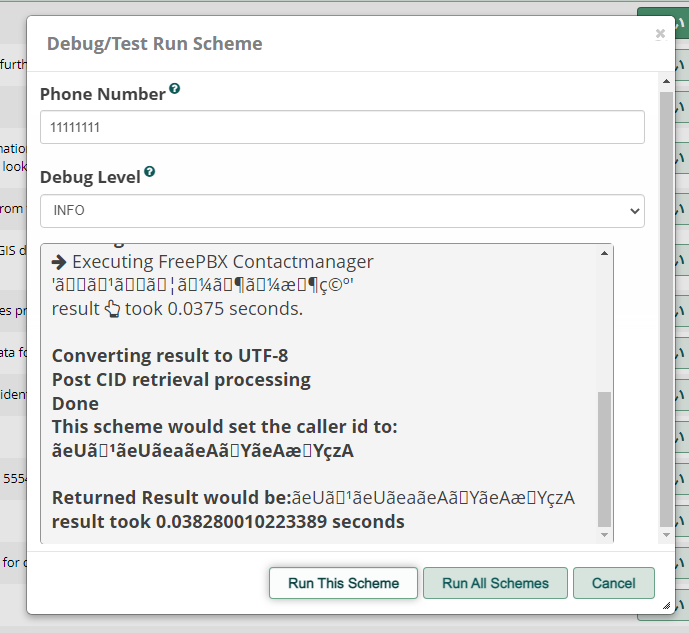
結論から申し上げると、原因はCID Superfectaのバグです。
ok…since nobody speaks German here and nobody was interested in the german umlaut conversion problem of CID-Superfecta…I had to find a workaround.
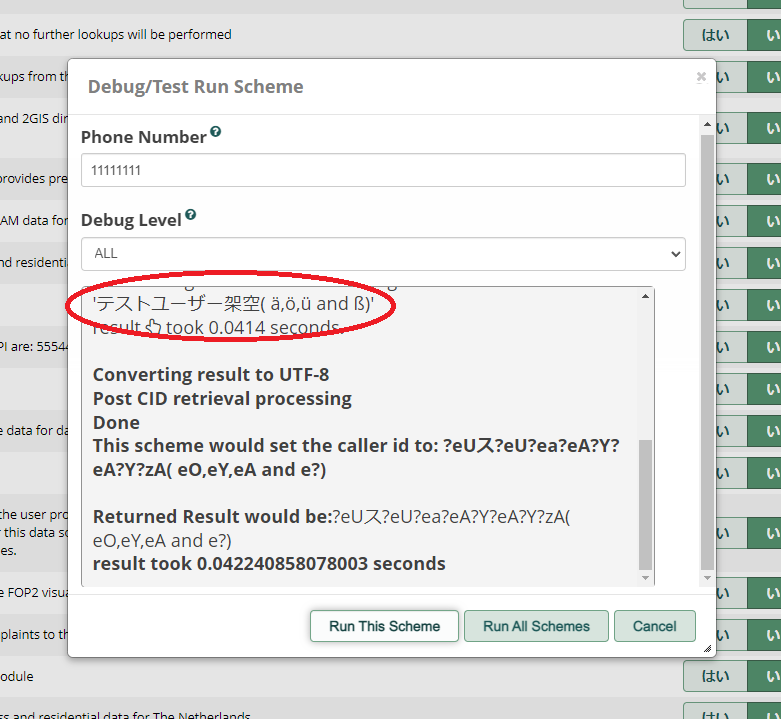
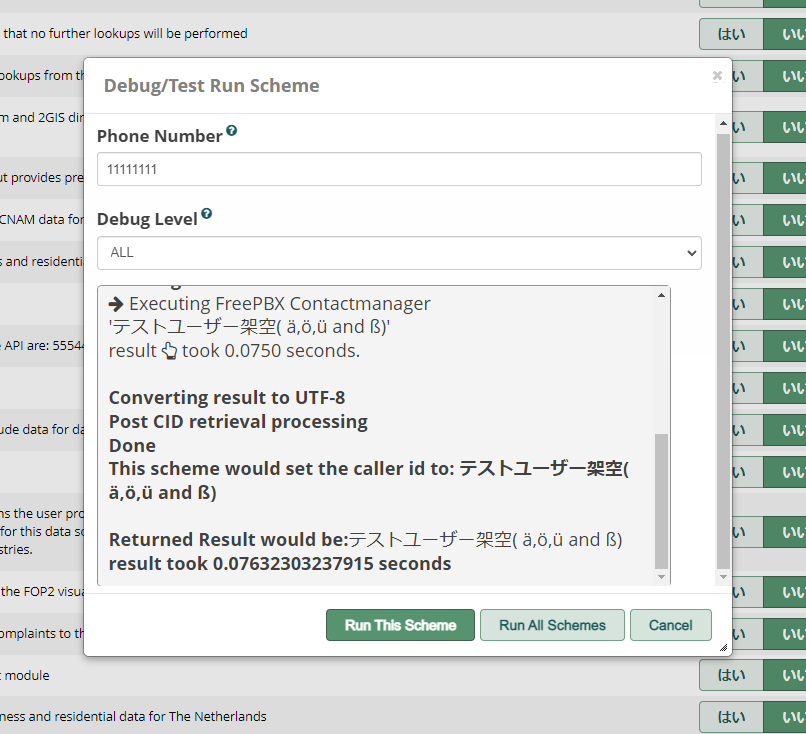
Depending on the charset of the strings the different source-templates produce…it either results in beautiful german umlauts and ß, or the umlauts and the ß are converted to ae, oe, ue…and ss
My edited superfecta.class.php is as follows…check line 191 and 205
まず、superfecta_single.php内の64行目でUTF8のデコード処理が行われています。
$caller_id = $this->_utf8_decode($caller_id);
_utf8_decode関数の内容を見ると、html_entity_decodeを通した後にutf8_decodeを通して値を返しているようです。
function _utf8_decode($string) {
$string = html_entity_decode($string);
$tmp = $string;
$count = 0;
while ($this->isutf8($tmp)) {
$tmp = utf8_decode($tmp);
$count++;
}
for ($i = 0; $i < $count - 1; $i++) {
$string = utf8_decode($string);
}
return $string;
}
html_entity_decodeを通すのはいいとして、なぜUTF8をISO-8859-1にデコードしているのかよくわかりません。
そして84行目で結果を表示する際に、わざわざISO-8859-1にデコードした結果を一時的にUTF8へ再エンコードして表示するというまた意味の分からない処理を行っています。
print "'" . utf8_encode($caller_id) . "'<br>\nresult <i class=\"fa fa-hand-o-up\"></i> took " . number_format(($this->mctime_float() - $start_time), 4) . " seconds.<br>\n<br>\n";
UTF8で受け取ったデータを変換して内部的にISO-8859-1で保持し、表示の際にわざわざUTF8に直すのであれば、最初からUTF8で持っていればいいように思います…
次に、stripAccentsを使って入力された文字列から分音記号を削除する処理が入ります。
$callerid = $superfecta->stripAccents($callerid);
このような処理が実行されます。
この処理にも正直何の意味があるのかわかりません。
それはともかく、このisCharSetIA5はIA5の文字コードを含むか含まないかを特に判別していないように見えます。
protected $charsetIA5 = true;
function isCharSetIA5() {
return $this->charsetIA5;
}
でtrueが返って来るだけなので、将来的に判別が必要になったときを考慮して処理を入れるようにしたが、現状英語が処理されても問題ないためすべての結果を処理するようになっているのでしょうか。
function stripAccents($string) {
$string = html_entity_decode($string);
$string = strtr($string, "äåéöúûü•µ¿¡¬√ƒ≈∆«»… ÀÃÕŒœ–—“”‘’÷ÿŸ⁄€‹›fl‡·‚„‰ÂÊÁËÈÍÎÏÌÓÔÒÚÛÙıˆ¯˘˙˚¸˝ˇ", "SOZsozYYuAAAAAAACEEEEIIIIDNOOOOOOUUUUYsaaaaaaaceeeeiiiionoooooouuuuyy");
$string = str_replace(chr(160), ' ', $string);
return $string;
}
_utf8_decode関数の内部でhtml_entity_decodeを通して、またここでも通しています。
そして仕上げに、223行目にてこの壊れた文字データをUTF8に再変換するという処理を行っています。
まとめると、UTF8のデータをISO-8859-1にわざわざデコードし、ラテン文字しか使用できず他は文字化けするように変換し、ブラウザ上にprintするときは一時的にUTF8でエンコードしてから表示させ、そこから分音記号の削除処理をされ、今度はそれをUTF8に直すというめちゃくちゃな処理を行っています。