FreePBX 15.0.37.1 Current Asterisk Version: 16.30.0
I have a customer who’s been up for a year. Recently they started stating that they have issues with call quality. Nothing has changed on this VULTR hosted deployment other than routine updates to applicable modules.
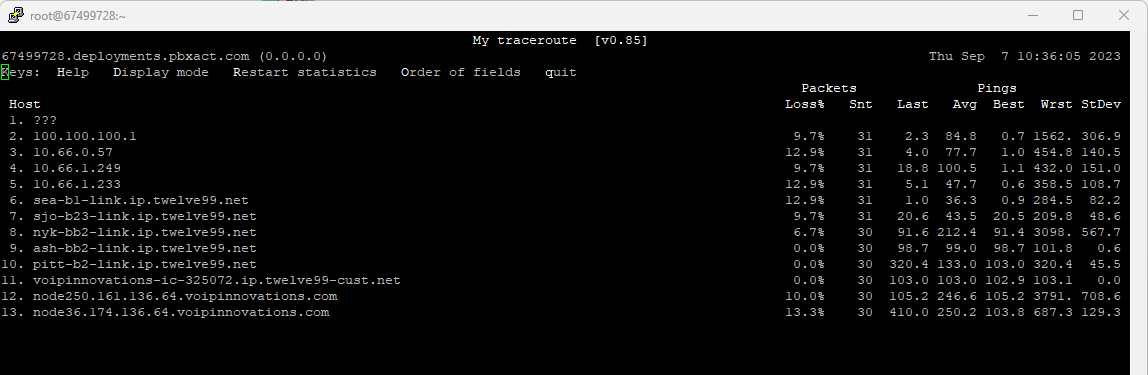
It has been difficult troubleshooting this as the customer had a faulty router right about the time the trouble began. The router was replaced and the issue persisted.
I have double checked firewall settings and all other settings that came to mind.
All numbers on the trunks/endpoints look textbook. Everything looks normal in the system that I have been able to find.
Any suggestions on how to isolate RTP media quality issues?
I had opened a ticket with VOIP Innovations with a call example and they state:
“We’ve observed issues with the quality of RTP media from your network. We suggest they investigate further internally to pinpoint the root cause of the poor call quality.”
Back in June of this year we were exploring options for hosting virtual instances of a PBX for our clients and I had setup an instance at Vultr just for testing and to check network quality and it ended up being really bad. Lot’s of dropped packets and routing issues out of the data center that we were testing from. I even created a support ticket and was told by their support staff that it’s all normal.
We ended up deciding on AWS after that because the same network tests done on Amazon instances (even though they are more expensive) were a night and day difference.
It looked to us like Vultr is well suited for certain types of applications where network quality isn’t the greatest priority. We had to go with Amazon in the end because the primary use here would have been VoIP.
Then start a test FROM your instance and the network where the phones are hosted as well as find a machine on the network with the phones and run mtr in the other direction, so to the vultr instance.
You’ll have to make sure that ping is allowed in both directions and to both destinations.
For science I would also start a second mtr test from both locations (so the vultr instance and the network that’s got your phones) to something like google.com. This would allow you to compare the results. If there is zero packet loss or latency from your phone network to Google but a bunch of packet loss or high latency from your vultr instance to google and between your vultr instance and your phone network then you know it’s gotta be the vultr network that’s the problem.
What you should see on a healthy connection is 0% packet loss. It certainly wasn’t 0% when we tested things on the vultr instance for us.
The only issue we’ve had with Vultr was actually an AT&T issue. They had (maybe still have) a problem with one of their routers that passed traffic to PCCW which is a major peering partner for Vultr, and it resulted in major packet loss. Vultr eventually dropped PCCW from their blend for their west coast datacenters because they couldn’t figure it out.
I wonder if there is something going on in asterisk? This instance has been a little problematic.
It had an issue where I was unable to apply the config from CLI or GUI. It would throw out memory allocation errors.
Probably not related, but I have the good old blank statistics window… it comes and goes.
I’ve had Vultr for about 4 years now. My PBX is in the Atlanta data center. I have never had any sort of packet loss. I had received a notice that they would be doing network upgrades in the early hours yesterday but I have seen no change in service. Perhaps the network upgrades were also affecting other data centers or were being made to clear issues.
To be fair. I didn’t hop data centers to see what the network results were in other locations. We picked a location that was close to us and our clients and since that didn’t look very good for us we just moved to AWS.
It is possible that network quality varies from data center to data center.