That is absolutely not awesome. That is asking for failure.
You currently have no idea if the system is even capable of successfully rebooting.
An article on the subject that I find informative: https://www.datamation.com/datbus/article.php/3909071/Should-Servers-Be-Rebooted.htm
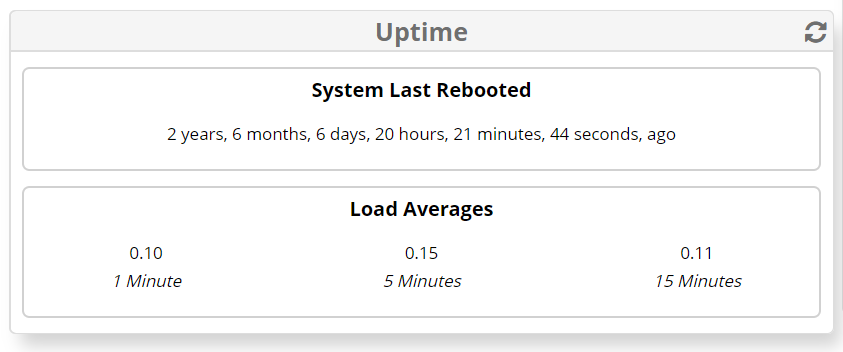
Actually I do - I snapped that screen-grab right before I rebooted it for Patches.
Go rain on somebody else’s parade - The mere fact that a Linux Production Box can be up for over 30 months and be working perfectly well is an awesome testament to Linux and Asterisk.
Coming from the Windows side of IT, I am very familiar with the need to reboot - Windows forces it but it still a good idea to do it occasionally when maintaining Linux boxes.
It’s posts like yours that create a very anti-community environment and really diminish the inclusive nature of the FreePBX community - if I had been asking why my FreePBX instance was acting wonky and then revealed that I hadn’t rebooted it in 30 months, you would be correct.
This is not the case at all - that box was working perfectly and is still working perfectly.
Go find someone else to hassle - That statistic is awesome and you don’t know what you are talking about.
This has nothing to do with Windows or Linux. Don’t inject your own bias in here.
This is a business continuity issue.
Yeah, woohoo, it is cool to have server X running with uptime X years. As a thought experiment that is neat. As a geek/techie, that is cool. But that has no place in business and PBX systems are, generally, in a business. What happens when something fails? The business has no idea if things will reboot correctly or not because nothing has been done in X years.
Not that I’m taking any side on this but after 20 years plus doing support I’ve learned one thing. Many, many many, many (to quote Captain Lassard) issues are prefixed with or the conversation contains “It was working perfectly until X happened. I can’t figure out why”.
Apart from kernel updates , there is no great reason to reboot, especially if you are proactively checking your backup process’ ability to restore to bare metal, but it is worth remembering that fsck by default will check your drives after 180 days on the next reboot , this can come as an unexpected inconvenience if you have large disks and an unexpected reboot.
JM2CWAE (and happy with 6 months and coincidentally my FreePBX machines are all at 174 days))
Ummm… you only want to reboot when installing, to make sure…
So in your world you mean all those enterprise NEC, Erricsson, Siemons, Panasonic Avays et al units out there all around the world that have been up for years and years, some over 20 years, should be rebooted every so often just for the sake of it?
How is THAT business continuity.
I most often agree with all of your posts Jared, but this one has me shaking my head 
I have rpi freepbx’s up longer as well.
rebooting is for when critical things warrant it.
Even most linux kernel exploits are safe on locked down PBX’s not exposed to the big bad internetz on a closed business intranet (public facing “open” servers of course not so safe)
I have a linux box on my private network - a file server, thats been up for years, its running a very early 3.2 kernel its thats old, no doubt if it was publicly accessible it would be owned in minutes, but its not and never will be, and a PBX is just code running on top of the OS, just like NFS/Samba/FTP/TFTP running on top of an OS as in my file server example.
I think the crux of all this is basically that sane failover, disaster recovery, etc. always call for those things to be tested at least once to twice a year in order to ensure your solution works. Because how good is your solution when the first time you need it after 2.5 years it doesn’t work because of X reason and no one knew that because they never tested outside of when they installed it.
Risk management is of course at the riskee’s level of confidence/exposure.
The legacy PBX you speak of don’t use Linux but hardened RTOS’s that only occasionally get changed and then usually to add function. Genereally the only problem they have is fraud caused by bad programming. So not really an apple to apple comparison.
Since I have never had one under my control with being power cycled at least yearly, yes, I mean exactly that. Just without the 20 year part.
Power cycling under control and then the main breaker to the building is tripped to simulate sudden power loss. Assuming the UPS stays online and provides the correct voltage I turn the Legacy system back on and monitor the UPS. Turning on the main power before the UPS actually fails.
@dicko is correct about the difference between those legacy systems and modern stuff that runs on a normal OS.
Exactly, I’ve had linux production servers pbx, samba, cobol, run well over 3 years.
This topic was automatically closed 31 days after the last reply. New replies are no longer allowed.