I am pretty new with using freePBX and I hope the mature community over here will help me understand develope deeper knowledge.
I have two endpoints which keep switching between reachable and unreachable states. Could I get some guide what the case could be. The log is as follows:
73847 [2022-08-23 16:05:20] VERBOSE[6434] res_pjsip/pjsip_configuration.c: Endpoint 23 is now Reachable
73848 [2022-08-23 16:05:20] VERBOSE[6434] res_pjsip/pjsip_options.c: Contact 23/sip:[email protected]:5060;ob is now Reachable. RTT: 97.513 msec
73849 [2022-08-23 16:06:10] VERBOSE[6434] res_pjsip_registrar.c: Added contact 'sip:[email protected]:5060;ob' to AOR '24' with expiration of 300 seconds
73850 [2022-08-23 16:06:10] VERBOSE[6434] res_pjsip/pjsip_configuration.c: Endpoint 24 is now Reachable
73851 [2022-08-23 16:06:10] VERBOSE[6434] res_pjsip/pjsip_options.c: Contact 24/sip:[email protected]:5060;ob is now Reachable. RTT: 95.899 msec
73852 [2022-08-23 16:07:23] VERBOSE[6434] res_pjsip/pjsip_configuration.c: Endpoint 23 is now Unreachable
73853 [2022-08-23 16:07:23] VERBOSE[6434] res_pjsip/pjsip_options.c: Contact 23/sip:[email protected]:5060;ob is now Unreachable. RTT: 0.000 msec
73854 [2022-08-23 16:08:13] VERBOSE[6434] res_pjsip/pjsip_configuration.c: Endpoint 24 is now Unreachable
73855 [2022-08-23 16:08:13] VERBOSE[6434] res_pjsip/pjsip_options.c: Contact 24/sip:[email protected]:5060;ob is now Unreachable. RTT: 0.000 msec
73856 [2022-08-23 16:10:10] VERBOSE[6434] res_pjsip/pjsip_configuration.c: Endpoint 24 is now Reachable
73857 [2022-08-23 16:10:10] VERBOSE[6434] res_pjsip/pjsip_options.c: Contact 24/sip:[email protected]:5060;ob is now Reachable. RTT: 10.262 msec
73858 [2022-08-23 16:10:20] VERBOSE[6434] res_pjsip/pjsip_configuration.c: Endpoint 23 is now Reachable
73859 [2022-08-23 16:10:20] VERBOSE[6434] res_pjsip/pjsip_options.c: Contact 23/sip:[email protected]:5060;ob is now Reachable. RTT: 2.904 msec
73860 [2022-08-23 16:11:10] VERBOSE[1167] res_pjsip_registrar.c: Removed contact 'sip:[email protected]:5060;ob' from AOR '24' due to expiration
73861 [2022-08-23 16:11:10] VERBOSE[13033] res_pjsip/pjsip_options.c: Contact 24/sip:[email protected]:5060;ob has been deleted
73862 [2022-08-23 16:11:10] VERBOSE[13033] res_pjsip/pjsip_configuration.c: Endpoint 24 is now Unreachable
73863 [2022-08-23 16:11:10] VERBOSE[6434] res_pjsip_registrar.c: Added contact 'sip:[email protected]:5060;ob' to AOR '24' with expiration of 300 seconds
73864 [2022-08-23 16:11:10] VERBOSE[6434] res_pjsip/pjsip_configuration.c: Endpoint 24 is now Reachable
73865 [2022-08-23 16:11:10] VERBOSE[6434] res_pjsip/pjsip_options.c: Contact 24/sip:[email protected]:5060;ob is now Reachable. RTT: 7.976 msec
73866 [2022-08-23 16:12:23] VERBOSE[6434] res_pjsip/pjsip_configuration.c: Endpoint 23 is now Unreachable
73867 [2022-08-23 16:12:23] VERBOSE[6434] res_pjsip/pjsip_options.c: Contact 23/sip:[email protected]:5060;ob is now Unreachable. RTT: 0.000 msec
73868 [2022-08-23 16:13:13] VERBOSE[6434] res_pjsip/pjsip_configuration.c: Endpoint 24 is now Unreachable
73869 [2022-08-23 16:13:13] VERBOSE[6434] res_pjsip/pjsip_options.c: Contact 24/sip:[email protected]:5060;ob is now Unreachable. RTT: 0.000 msec
This comes up about every three days. I’d suggest looking back at earlier postings.
My take on it is it generally means you have an overloaded network, and the fact you are getting 95ms round trip times even when things start to work again, does tend to suggest that is the case.
Thank you very much. May I ask that according to your knowledge, what could be the cause of overloading as I only have two endpoints which aren’t doing any calling at the moment.
P.S: I couldn’t any previous question that discussed overloaded network.
I don’t know your network topology, but IP networks are contention networks and at, all but the very first hop, you will be sharing bandwidth with other traffic.
Thank you.
Is there any way I can increase the time period after which the ‘check’ is performed. Since this switching between avaliable and unavaliable doesn’t affect my call and voice transmission occurs as normal.
Sorry for my ambigous statements :). I couldn’t find the qualifyfreq in any files you mentioned over here.
Thank you for the link. Is it necessary to use trunks to increase the time period? I was using extensions (two softphones) without any trunks. Any way out or I should necesssarily use trunks?
I missed the reference to extensions. I seem to remember that most people have problems with trunks.
The same underlying options exist, because there is no real difference between a trunk and an extension at the SIP and Asterisk levels, but there may well be no GUI field, so you will have to set the underlying parameter as custom configuration.
The underlying setting for chan_pjsip is qualify_frequency, which goes in the type=aor section.
However, if you are messing with these timeouts, you are normally fixing symptoms, rather than the real cause.
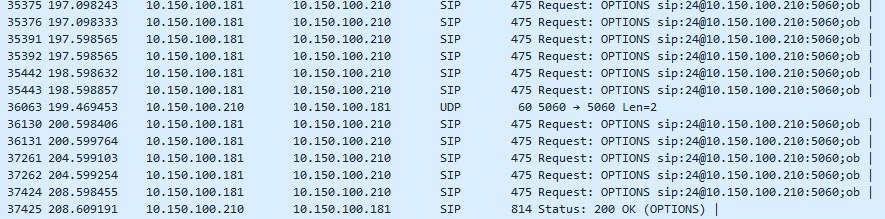
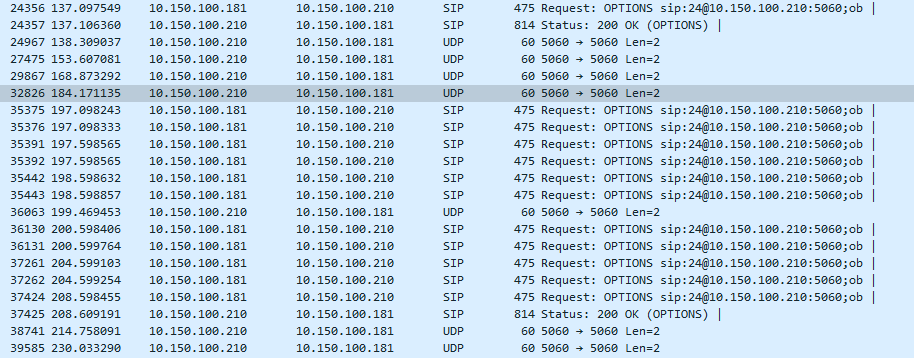
Thank you for the reply. I have checked that my system isn’t overloaded and the traffic is in range of few KBs. I have montiored the process through wireshark to see how the SIP OPTIONS packet is responded. The moment the endpoint is reachable. The communication is as follows:
P.S: 10.150.100.181 is the sip server and 10.150.100.210 is endpoint.
The moment the communication fails, it seems that the server is sending back to back option packages with so less interval and decides that the endpoint isn’t their although the endpoint sends an ok back.
There is something a bit funny in that it seems to be sending pairs of OPTIONS to the destination, but every single OPTIONS should produce an OK. You are hardly getting any back. The network or the peer is badly broken. That trace supports the theory that there is something wrong with the network.
If one ignores the double sends, what one sees here is an exponential backoff, with 500ms, 1,000ms, 2,000ms and 4,000ms gaps. It is getting extremely desperate to elicit a response, that should have arrived within single figure milliseconds. They are not being sent back to back, except as pairs, but rather at increasingly doubling intervals. The retransmissions stop when any reply is received, or Asterisk reaches the point where it considers the contact unreachable. The fact that you are getting a lot of them is a symptom, not a cause.
Given that you are receiving some sort of, short, keepalive packet, and that the actual OK seems to come close after the last retransmission, I’d suggest that the network is throwing away most of the OPTIONS requests.
If you are able to get logs from the peer, you should look at them to see if it is receiving the OPTIONS, and if so, if it is replying to each one.
I’m not sure what would cause the doubling, unless, maybe you have two definitions of the same contact.
What type of softphones are being used? There is a common problem with softphones handling backgrounding and sleeping. This could be a case of the client not responding to the OPTIONS because it is backgrounded on the device.
These two sends are about 100 microseconds apart, which basically meant they were sent in quick succession. I would expect only one to be sent at this time.
That was absolutely true. The case was that both enpoints had the same MAC address. . Thanks for the help! Changed the MAC address and the error doesn’t appear now.