Hi,
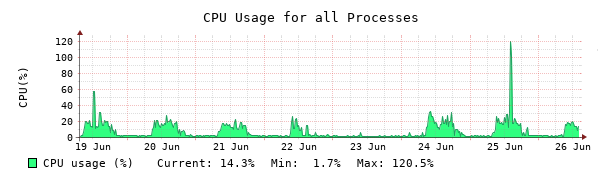
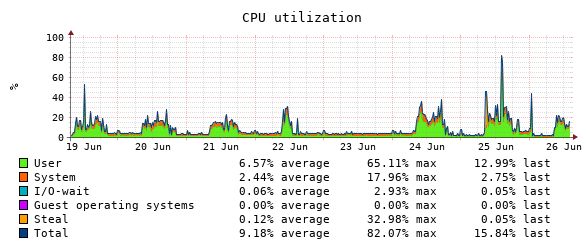
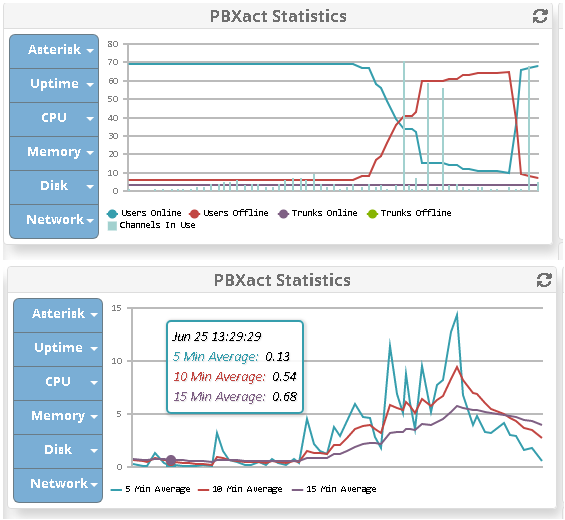
We have a PBXact 100 user system running in the cloud and at 13.54 today all extensions started going offline. The 100 extensions are split across 6 different sites using sangoma phones.
During the outage Asterisk -r just kept displaying a chan_sip.c: Autodestruct on dialog messages every second
We ran a fwconsole stop and fwconsole start and everything started coming back online again, so now we are trying to figure out what this issue was.
We can see the Warning message start in fail2ban here
[2019-06-25 13:50:48] WARNING[2552] chan_sip.c: Autodestruct on dialog ‘[email protected]:5160’ with owner SIP/XxxxxXxxx-SBC1-00001827 in place (Method: BYE). Rescheduling destruction for 10000 ms
The SBC referenced in the line above was stable and no other clients connected to that SBC were effected.
and then the extensions etc start failing in the full log
[2019-06-24 13:54:33] VERBOSE[9637][C-000021cb] app_dial.c: Everyone is busy/congested at this time (1:0/0/1)
[2019-06-24 13:55:00] VERBOSE[12640] res_pjsip/pjsip_configuration.c: Endpoint XXX is now Unreachable
[2019-06-24 13:55:00] VERBOSE[12640] res_pjsip/pjsip_options.c: Contact XXX/sip:[email protected]:39749 is now Unreachable. RTT: 0.000 msec
The system has a quad vcore cpu, 8GB Ram, and 100GB SSD.
Any hints or tips would be greatly appriciated,
Thanks
Dave
PBXact 14.0.13.4
PBX Firmware:12.7.6-1904-1.sng7
PBX Service Pack:1.0.0.0 Current Asterisk Version: 13.22.0
We were also seeing some Asterisk Task Processor Queue Size Warnings but not sure if this could be related as they seem to happening quite often every day.
I have read here https://blogs.asterisk.org/2016/07/13/asterisk-task-processor-queue-size-warnings/ that we should start disabling parts of the PBX we dont use. I’m wondering how many people do this or get this error.
Our client is still asking how the issue happened that all the phones started disconnecting so we are hoping for any guidance to see what the cause might have been.
I’m not deflecting, but this looks a lot like a network problem. A couple of years ago, there was a guy that was having a similar problem, and it turned out to be a bad network switch. The endpoints going unreachable is (on its face) a network problem.
The tricky part, though, is that it could be anywhere in your infrastructure, including the network card in the server, the switch, the POE injector (which could be bricks or could be a POE switch), or some other device in the network.
Other places to check include the firewall (which could be blacklisting phones for no reason whatsoever) and the other security features in the server.
Hi Dave,
Thanks for the reply, it’s actually held on a shared cloud server instance so we don’t really have much control over the underlying hardware where it sits.
Each of the 6 different sites all started losing connections at the same time so I expect it not to be any of their local router/firewall/switch hardware.
All sites have their external IP address Trusted in the PBX so they cant be blacklisted.
It does raise a flag to look into moving the client to a dedicated server etc but will increase the server spec and see if it helps before discussing a move to a dedicated system.
As soon as we ssh’d onto it and ran a fwconsole stop and fwconsole start the phones across all 6 sites started coming back online again.