Hey all, I’m usually better about diagnosing these end-to-end issues but I’m on about 1 hour sleep. We switched everything to FreePBX and we’ve been fine for 0-20 calls at once, but 20-50 has gotten pretty crazy. Some calls are seeing 2-3% packet loss and I’m getting a lot of complaints. I have dual 100/100mbit fiber connections and our tunnel from our office to the FreePBX in Amazon reports no packet loss, so I’m thinking the issue is with the switches on our side, maybe just too much traffic on the voice VLAN. Anyone have any tips on how I can get methodical about figuring this out?
What type of switches are you using Gigabit, 100/10…? Is there any other traffic on those switches. A quick calculation tells me that 20-50 calls should be taking 2-5Mbps… should be much of a issue for most switches.
It may be more of an issue that the hardware you are running this on is choking.
Is your Dual 100/100Mbps set as a Load Balancing, or failover? Could be that after a certain amount of traffic it starts to load balance.
If you have switches available, try to place voice on their OWN switch. You can eliminate VLAN and hardware with this step. As far as Amazon, they are Virtualized enviromenets, no? If they freeze, they won’t know it, so try analysis off the Virt environments.
There are some ideas.
I got a network tech on the phone and he had some ideas for optimizing the VLAN config, so I tried that and it seems to have fixed most of the dropped packets.
The Amazon VM is a Medium.T2, it has 2 vCPUs and 4gb of RAM. I’m not sure how to interpret the FreePBX dashboard “CPU” graph to tell if it is maxing out.
Our dual 100mbps fiber is essentially bonded. It goes from a physical Peplink router here which then bonds it and sends it to a Peplink VM in Amazon next to the FreePBX instance. This allows it to “shotgun” the same packets across both ISPs at once and take whichever packets get there first, which is supposed to smooth out jitter and packet loss. The Peplink is reporting no packet loss on that tunnel which does make me suspect our switches more.
I can’t put the phones on their own VLAN, as they pass ethernet to everyone’s workstations. Too late to run more ports in our building unfortunately.
Thanks for the ideas, I’ll see if the VLAN qos config helped and I’ll try to analyze our Amazon instance.
I hate to say this, but that’s your mistake. People have WILDLY different results (from ‘perfect’ to ‘terrible’) without any rational explanation of why.
I strongly urge you to host it yourself, or, use a better hosting provider.
Personally, I use Vultr and if you use this signup link – SSD VPS Servers, Cloud Servers and Cloud Hosting - Vultr.com – you get a free $20 credit and I get $30. They aren’t FreePBX experts by any stretch of the imagination, but everyone seems reasonably happy with them for providing hosting that actually works.
If you want REAL hosting, I suggest you sign up with one of the companies that specialize in that - see Hosted FreePBX | FreePBX - Let Freedom Ring
AWS isn’t some magical black box where nothing can be monitored. I’ve had the thing running fine for half a year and only now with 10 times the simultaneous calls am I having dropped packet issues. We’ve had a constant ping to FreePBX of 10ms for the entire 6 months, and we still do. If there’s no packets reported dropped in the tunnel from our router to there, that only leaves our switches and the FreePBX instance itself. If it is the latter, I’m sure I can find out if the CPU can’t handle the load.
Anyhoo, AWS wasn’t my first choice, I was going to host in-house with High Availability but my bosses insisted on AWS and only AWS. Honestly I think it is excellent and I trust their NOC and uptime more than some place you’re passing referral links for, no offense.
i don’t understand you comment “I can’t put the phones on their own VLAN, as they pass ethernet to everyone’s workstations.” that is exactly why you use vlans. put the phones on something other than the default vlan and leave the port on the phone set to the default vlan (or no vlan). how you set up your vlans is dependent on the hardware you are using. but a relatively easy way to set it up is to make sure your phone config on the pbx has the proper vlan info in it, make sure you have a dhcp server for both the default vlan and the phone vlan (can be the same server) and make sure the switches are configured properly. then if you pull a phone out of the box, the default vlan dhcp server should point the phone at the pbx, the phone pulls its config, the phone switches to the vlan defined in its config, gets a new ip address from the phone vlan dhcp server, pulls its config again from the pbx but this time using the vlan and away you go.
the use of a separate vlan, again assuming the right hardware, should allow you to manage the traffic on each vlan - i.e. you can limit how much traffic the computers can use.
I misspoke, the person I was replying to suggested I put the phones on their own physical switch, as opposed to their own VLAN. My phones are on their own VLAN of course, I meant to say I can’t put them on their own separate switch as they pass data to the PCs.
is your fiber pipe dedicated to voice? or is it shared with the computers in the office? if it is shared you might need to do some traffic shaping to ensure that voice always has enough bandwidth.
i am also curious as to where you are seeing the packet loss? at the phone?
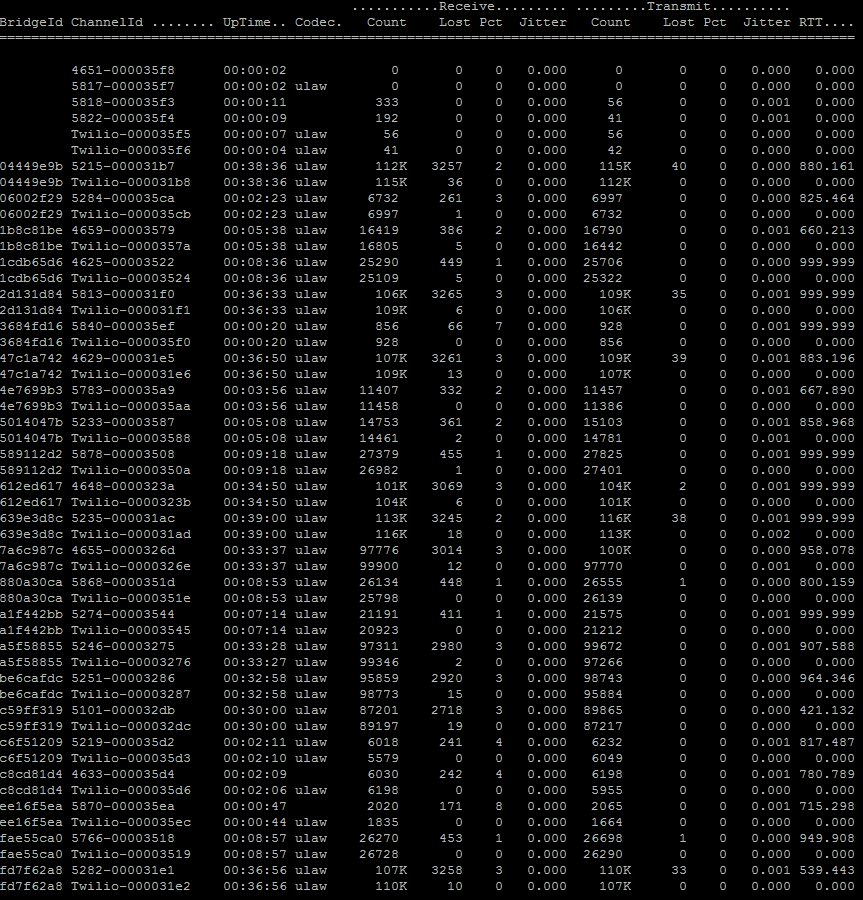
We were seeing packet loss reported from the Polycom phones themselves and from the Asterisk PJSip Show Channels command.
Last night I got a network tech to check out our switch configs and while QOS was set on our voice VLAN, it wasn’t tuned as well as it could have been. The packet loss is dramatically reduced so far today, everything is below 1% packet loss and everyone says it is fine, though we have only hit 30 simultaneous calls today, not the 50 like yesterday. Fingers crossed though!
well it sounds like you are on the right track - you may have to so some throttling on the default vlan (or whatever vlan the computers are on) or spend lots of time tuning QoS.
and all this QOS is why I stick it on a separate switch. Don’t have issues… Also, I tend to have separate Data and voice networks ( I guess goes without saying… duh). In a pinch, there is a backup jack in case something goes wrong. On the Firewall I prioritize traffic from PBX IP and voilà.
if you have the luxury of having separate data and voice networks then life is certainly much easier but more often than not we run into situations were there are not enough network jacks and that is where vlans and QoS in the switches becomes necessary
if you mean traffic shaping when you say you are prioritizing traffic then yes it is a must when using a converged network. however if you truly mean setting a higher priority for voice traffic, then i think you will find that data traffic can cause poor voice quality. in a converged network it is essential to use a sip aware router (session border controller) that can do traffic shaping (change bandwidth allocation in real time) whenever you have a converged (data+voice) network. with a good SBC you can have good voice quality on a slow DSL line.
I just spent an hour adding dozens of caller IDs to the Caller ID Management module, then reloading. At the last couple reloads I noticed they were taking forever. Right now I tried to place some calls. The calls take a few extra seconds to go through and are breaking up. The asterisk show channels command is showing packet loss over 100%, and the dashboard is suggesting that Asterisk
Does anyone know if there’s more commands I can run or logs I can check to determine the source of these performance issues?
Here’s a print out of graphs for:
-
CPU (Hour)
-
Network (Hour)
-
Asterisk (Hour)
-
Uptime (Hour)

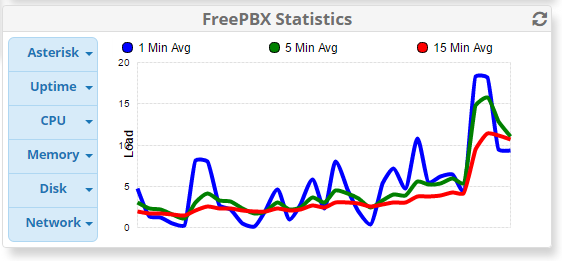
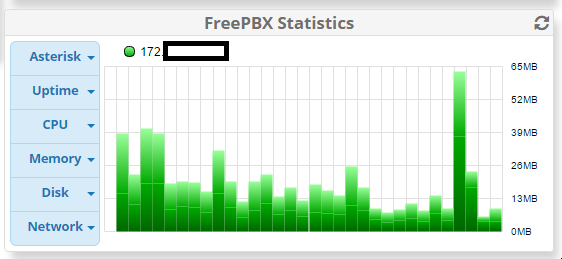
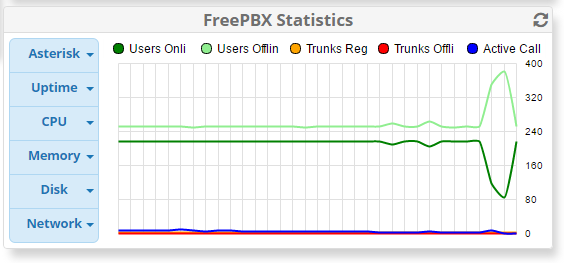
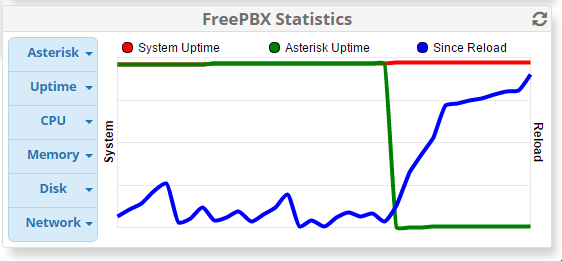
Things have been fine for the last week since I increased the CPUs on the Amazon instance, and increased the storage from 10gb to 100gb (Amazon recommended I delete the swap partition as they said it shouldn’t be used with Amazon instances). Today something finally went wrong; about 30 calls all dropped at once. I immediately checked the server and all 4 vCPU were totally saturated.
I rebooted the server and everything came back up fine. I opened a paid support ticket with Sangoma but I figured I’d document it here as well and see if I can crowdsource the root cause. I have detailed SAR logs if anyone is interested as well. Any help is appreciated!
Here’s the TOP output and where you can see the Asterisk lines drop again:
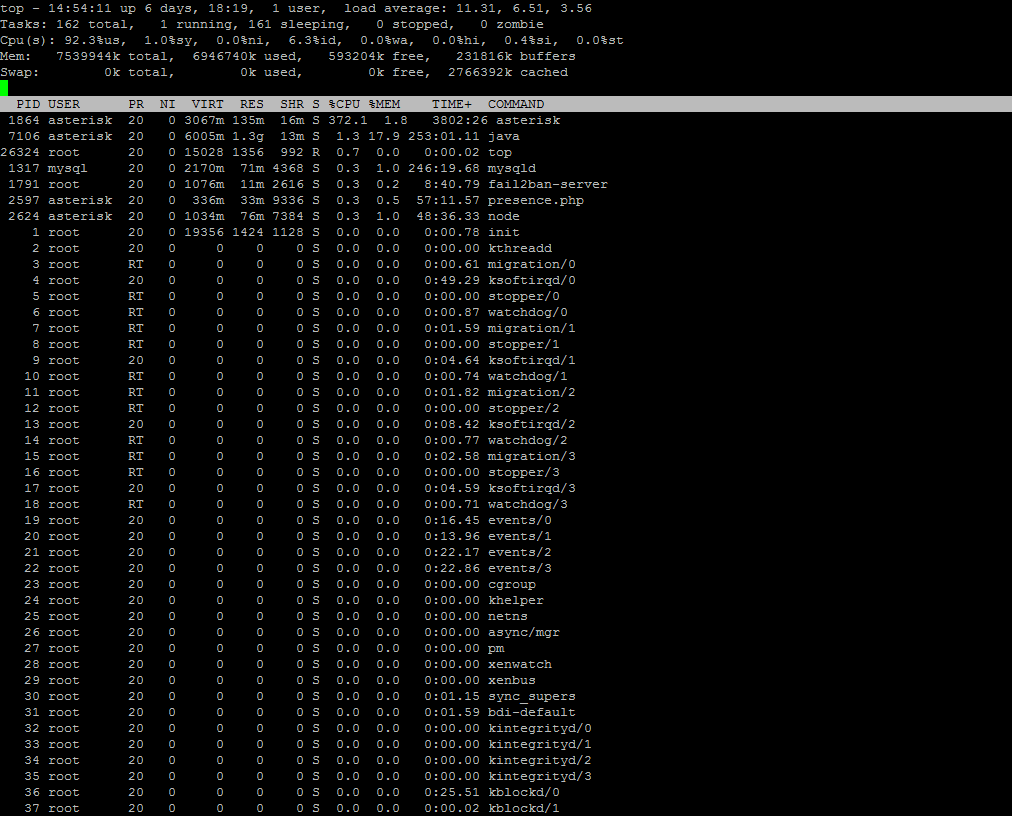
Free tip. Dont use Amazon. Bet the root cause is the host you are on is over loaded with other instances.
1 Like
I’m assuming you’re the guy I reached at Sangoma when I called in? I understand you’re all very down on Amazon, and indeed from the start I wanted to host FreePBX HA on my own hardware at the office, but my bosses insisted on Amazon so my hands are tied.
Amazon does give the option of “Dedicated Hosts”, which are more expensive than ordinary instances but are alleged to be insulated from the overprovisioning or CPU spikes of other customer’s instances. Here’s a quick article I found: http://www.infoworld.com/article/3008225/cloud-computing/amazon-dedicated-hosts-bye-bye-to-noisy-cloud-neighbors.html
I’ll get in touch with Amazon and confirm if switching my instance to a dedicated instance would guarantee the CPU performance. Would anyone know if CPU spikes from other customers would be detectable from my own server?
No I would not be a person you would talk to when you call into Sangoma. But hey what do I know. I will shutup and let you go down your own road.
1 Like
any vm environment is vulnerable to things other vms do on it. you really should be on a dedicated host rather than a shared one. i am not quite as negative on amazon as tony is, and am a big fan of hosted pbxs - it makes very little sense these days (to me anyhow) to invest in hardware that you have to maintain. sure you pay a little more if you use amazon but it becomes their problem to make sure the hardware and networks are up, performing well and are secure. But a shared server is not what you want for your pbx. it works fine for an email server or even a basic web server but if you intend to provide decent phone service, then switch to a dedicated system. what you might want to do is to check with people (not amazon) that do host systems like freepbx to get an idea of cost and then compare that to the cost of a dedicated amazon host and use that am ammunition with your boss.
1 Like
I have no issues with hosted systems. My issues is with Amazon or other providers that do not optimize for real time voice communications as they are just a general hosted provider. That is my point. Hosted is great and I 100% agree.
1 Like
I hope I wasn’t conveying a sassy tone or anything. Like I said, it wasn’t my first choice, and I’m not just blowing off your advice, Tony. I did call up Amazon and the tech was swearing up and down that at the exact point in time where our shit went bonkers, there was no unusual load from the other customer’s VMs on the host machine I was on at all. Everything was quiet, but my instance spiked to 100% CPU on all 4 cores.
Here’s the minute-by-minute SAR logs from that time:
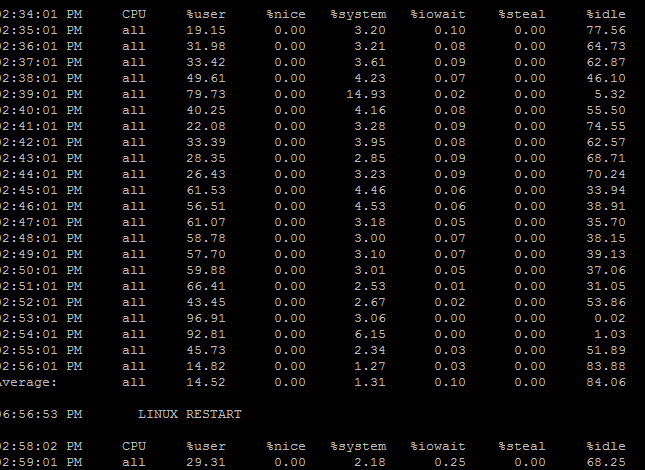
The “server restart” is off by a few hours because it sets the time zone a little after the reboot. So you can see things go from 60% CPU to 43% then suddenly to 96% and that was exactly when all 30 calls in the office were dropped.
Filtering for warnings at that time shows some weird stuff, I’m still searching on Google to see how to interpret it:

I was speaking with Amazon and we’re probably going to spin this up on a dedicated host just to rule out the chatty neighbors.
One other thing is that our Asterisk root logs are set to a verbosity of 3… do you think that would generate an undue strain on the CPU to be logging that much, or is it negligible?
Our server is on a C4.xLarge instance, which uses 1/8th of the CPU resources on a two-socket Xeon E5-2666 v3 machine… everything I’ve read about Asterisk suggests that should be massive overkill for 30 simultaneous calls… so I guess what I’m asking is, has anyone seen CPU usage like this happen under non-Amazon circumstances? It’s also entirely possible that Amazon is messing up, PLUS I have something configured inefficiently on FreePBX as well.