I just upgraded my High Availability system to FreePBX 13. Everything on the master node was fine. On the upgrade on the standby I encountered the upgrade hang error. I proceeded as the wiki suggested, but meanwhile my first terminal window where I initially did the upgrade timed out, so I don’t know if the upgrade on the standby node was successful as well.
How can I verify that the upgrade to 13 was successful?
I hesitate to rejoin the cluster without being sure.
After a failed reboot of the standby node, I found that I had a corrupted kernel installed with the upgrade to 13. I ran the upgrade script again and what I now have on the GUI is a “The DRBD Versions are not identical between nodes. Ensure both nodes are up to date with all packages.”
And what do you think about the upgrade that apparently didn’t continue after I had to kill the crmd process due to the bug in pacemaker. (Putty ssh session timed out unfortunately).
Shall I run the upgrade script again and will that fix the issue? Or is my install broken completely?
Thanks Rob.
Ran upgrade on active following exact steps on the wiki. No problem.
Than ran it on standby tonight. There the upgrade didn’t complete. Reboot failed with Kernel panic error.
We managed to bring the machine back, but there is no cluster replication.
What can I do if in the middle of the upgrade, my ssh session terminates (which is a possible cause) and the upgrade doesn’t continue?
Your wiki and website was down yesterday for a couple of hours, maybe your download servers were affected as well, don’t know. Anyhow we are left with an incomplete upgrade on one machine and don’t really know where to start fixing. I hope I don’t have to wipe the whole server and start from scratch.
That’s not what you said, you said there wasn’t any replication between the nodes?
If it’s just the second node that’s broken, it might just be easier to reinstall the machine from the latest ISO. Make a note of the deployment ID before you reinstall it (although it should auto-detect and automatically assign the licence back to itself).
We got the cluster back up, fixed error “The DRBD Versions are not identical between nodes. Ensure both nodes are up to date with all packages.”
Now our issue is the following: We had the problematic server on master, the other node joined the cluster. We put the master node into standby, which instead of going into standby actually rebooted and now gives this message in PCS status:
[root@freepbx-b ~]# pcs status
Error: cluster is not currently running on this node
The other node came back fine as the master.
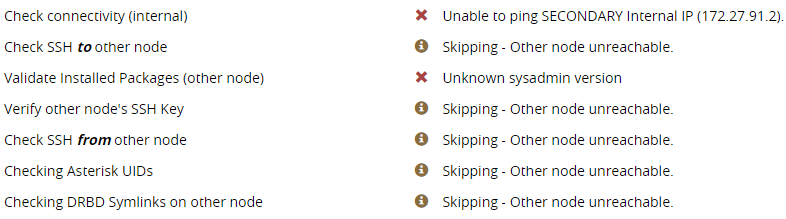
Check connectivity (internal)