I am trying to understand the total downtime impact for the upgrade path from 6.12.65-32 to 10.13.66, all the way up to the latest incremental update. My team manages an HA cluster for a 24x7x365 call center, so outages must be avoided when possible, and carefully planned for when they are unavoidable.
Per this wiki article, the jump from 6.12.65 to 10.13.66 causes a ~5-minute outage and possibly another short outage. Cool, we can plan for that. After we’re on 10.13.66-1, what about the incremental updates to 10.13.66-11? The wiki has another general process for performing these on an HA cluster, but no indication of services impact to an HA cluster during that process.
So, anyone who has done this:
Approximately how much downtime do these incremental updates incur for an HA cluster, and when in the update process does the downtime occur?
Where in the process should we reboot following the updates? Should we upgrade both servers, then reboot each server while it is in standby mode?
Can we use the System Admin module to perform the updates all in one batch, to consolidate downtime and reboot only once?
When upgrading the distro 6.12.65 to 10.13.66, if everything goes well, your outage should be very brief.
When you follow the instructions on the wiki, you arrive at a point where you have upgraded the distro on both machines, both nodes are online and the slave node is already rebooted.
Then the wiki tells you to put the active node into standby, and that’s the only moment where an outage occurs (until the slave node becomes master and all services are started).
The incremental updates to anything after 10.13.66-1 don’t cause outages per se and don’t require reboots. When using sysadmin pro GUI update function to do those, the cluster is automatically put into maintenance mode, but this doesn’t affect calls.
However, after having upgraded the active node, you are required to put the master into standby to upgrade the new master server as well.
“Since the Cluster is based on the FreePBX Distro, you should always follow the Upgrade Scripts for the FreePBX Distro here. Upgrade Scripts should be run on the Master Server first and, once completed, put the Master Server into standby and upgrade the new Master Server.”
These incremental updates don’t cause outages, except when putting the active into standby to upgrade the new master.
No reboots required for the incremental updates. Sysadmin pro puts the cluster into maintenance mode automatically and back.
This doesn’t require a reboot (But a change of active nodes to upgrade on the second node too, causing a brief outage). You can update in one batch.
What I would still ask Rob is how important it is to use the FreePBX GUI 13 upgrader first to upgrade to FreePBX 13, prior to upgrading the whole Distro, cause the wiki states:
“Upgrading is only possible when you are running FreePBX 13. Before attempting to upgrade to Distro 6.6, ensure you are running the latest FreePBX 13 version, and associated modules”
To summarize and confirm, we should expect two outage windows, both caused by HA failover between master and secondary nodes: first at the end of the distro upgrade, and second halfway through the incremental upgrade.
Just two questions remain then:
The wiki says we must upgrade to FreePBX 13 before running the distro upgrade to 10.13.66, does that incur additional downtime? The wiki isn’t explicit about this. (@GSnover, it sounds like the FreePBX upgrade must be performed before the distro upgrade.)
We’re upgrading in part to mitigate the glibc vulnerability described in CVE-2015-7547, for which FreePBX hasn’t released a patch for the 6.5 distro, only for 6.6. Does anyone (perhaps @tonyclewis) know whether we’ll receive the patched glibc package during the distro upgrade to 10.13.66-1, or whether the non-vulnerable glibc is packaged with one of the later incremental upgrades on the 10.13.66 track? If the latter case is true, I think another reboot may be required after the incremental upgrades to ensure full protection against CVE-2015-7547. RHEL describes a way to restart processes still using the old glibc libraries without fully rebooting, but this is labeled a “temporary workaround” that is “not supported”. I’m inclined to heed their advice, as FreePBX is ultimately RHEL under the hood!
No. Upgrades through the GUI never cause outages (well, they shouldn’t!).
So, as this has been asked a couple of times, let me just be explicit: Upgrading from FreePBX 12 to FreePBX 13 is painless, and does not include any outage, at all.
The process of upgrading a HA cluster is FreePBX to 13 (which upgrades both nodes), and then each node from 6.5 to 6.6. If you follow the wiki religiously, you won’t have any problems. Just be aware that you will most likely have the pacemaker upgrade freeze, and you’ll have to manually kill it. There’s nothing I can do about that.
You will have it as soon as you upgrade to 10.33.66-1.
Both of your questions are RIGHT at the top of the wiki on how to upgrade. Please PLEASE read and follow it.
Sorry - maybe I am dense (Maybe?) - I am currently at 6.12.65-26 and the instructions for non-ha say you have to apply the updates sequentially and can’t jump because they are not cumulative. Is it different with HA?
So for instance on a Non-HA machine, I would execute the following:
I have read the document and I don’t see this addressed but I haven’t done updates since I installed and now I am worried. And I guess the answer to the question above will also answer the question for updates after the Version upgrade.
And one last question relevant to HA - I have a VERY busy system (which is why we bought HA!) and I think my logs are getting LARGE:
After you have upgraded to FreePBX 13, let System Admin get you up to 65-32. Then follow the wiki.
They are just log files. They should be rotating automatically, but you can have a look. If there are old files you don’t need, you can simply delete them. If a single file is excessively large, that’s unexpected, and it means a log is not rotating correctly.
On an ordinary system, you get FreePBX 13 as part of the upgrade. I’m not sure what happens on an HA cluster, because the very first line of the recommended HA upgrade method states:
I have successfully upgraded a few clusters using the instructions linked above. I have also messed up a cluster by winging it.
Sphincter Check! I finally upgraded my cluster since NOBODY is there right now being a Holiday Weekend.
The procedure worked very well with one VERY scary moment - I had updated the primary machine to 10 successfully and it was time to upgrade the standby machine - I had a web page open with the cluster status open while the script was running on the standby machine - SEVERAL times the cluster status indicated problems - and the cleanup hung on the standby node - it did NOT hang on the primary (?) - but right as the script was finishing, the cluster status failed to a web failure with cannot connect to MySQL and looking at the pcs status, everything was stopped/hung.
I rebooted the standby since it was done, but it made no difference to the status of anything, so with no other option, I restarted the primary - it came up fine, and then I was able to put the standby node back into service, and a Cluster Check says everything is happy and it seems to be working perfectly - just in case anyone else runs into this.
Continuing adventures - did all the updates on Sunday the 29th - this morning is when everybody came back and started pounding it - at 8:30 the a-node started dropping phone registrations, the cluster tried to switch to b, failed and they went totally down - reboot of both cluster members brought the cluster back up happy and it is still processing calls now.
So after running non-updated for 1 year and 3 months, we have our first crash right after updating to current. That is a bummer to say the least!
Couple of questions:
What is more stable for Cluster right now - Asterisk 11 or 13 - I am running 1.11.22 right now (current) but if 13 is more stable, I will happily switch.
What is the method for switching versions - similar to the procedure for updating the OS Version? Has anyone done this?
@GSnover, have you had any troubles since your cluster failure + reboot in late May? We are preparing to perform this update ourselves and your story is the only thing that still gives me pause.
Nope - still running 11.19 though - it has been rock solid since rolling back to 11.19 - I am just surprised that such a serious bug made it into a production build of Asterisk - but perhaps that is an indication of how few people use Queues - we use them all the time, but maybe we are weird.
We tried the distro upgrade last week, and encountered some issues which took our cluster offline.
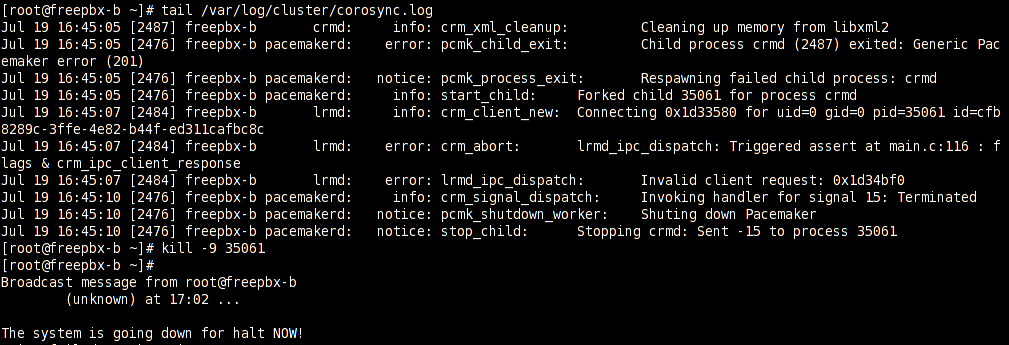
When I ran kill -9 on the crmd process to resolve the stalled yum upgrade, (per the guide here), freepbx-a shot freepbx-b in the head.
Jul 19 17:02:26 freepbx-a pengine[41298]: warning: pe_fence_node: Node freepbx-b will be fenced because our peer process is no longer available
Jul 19 17:02:26 freepbx-a pengine[41298]: warning: determine_online_status: Node freepbx-b is unclean
Jul 19 17:02:26 freepbx-a pengine[41298]: warning: stage6: Scheduling Node freepbx-b for STONITH
This crash broke some RPM packages on freepbx-b, including the kernel and FreePBX, which were reinstalled by @xrobau.
Secondly, while swapping a PRI cable between the servers after the failover at the end of the distro upgrade, our onsite contact accidentally disconnected the network cable between the two servers used for inter-node communication. This was our bad, but it caused freepbx-a (while explicltly in standby mode) to STONITH freepbx-b (while it was the active node), rather than the other way around. This caused a much longer outage than we were prepared for.
FreePBX support is now recommending that we rebuild freepbx-b completely. This may be the solution, but I’m concerned that the STONITH/fencing is misconfigured in the HA module and will continue causing grief. According to the man page of cman(5) on our servers, we should have this for a two-node cluster in /etc/cluster/cluster.conf:
<cman two_node="1" expected_votes="1"></cman>
But, I don’t see this, and I’m not an expert on this set of clustering tools. I’ve asked FreePBX support to investigate and advise.
That specific point I can weigh in on - right after we installed the cluster, but before we went live with it, the whole cluster tanked and neither node would come up - come to find out the onsite techs for the customer took away all the cluster’s access to the Internet - so licensing failed, switchover failed because of licensing, and then it self destructed.
So we shut down node-b, and brought node-a back up and made it all happy again - then we did indeed nuke node-b, recreated it from scratch, and then re-synced and it worked fine.
So if they are telling you to do it, do it - I have already gone that route and it worked for me!
Greg, that’s an interesting problem, and a bit scary to hear the cluster can forget its licensing (and how to do its job) if it loses internet access.
We never lost the internet connection, only the heartbeat link last week. In the past few days, @xrobau and I investigated and couldn’t find a reason that we actually needed to rebuild freepbx-b, or a configuration issue with the clustering.
So, we tried to fail over again today. Unfortunately it didn’t go well - Asterisk would start on the other node but then crash. It turns out our CDR table (with over a million rows) was corrupted, and that was preventing Asterisk from starting on either server. @xrobau repaired the table and hopefully we are OK now, pending another failover test next week.
Then, maybe we can start the incremental Systam Admin upgrades.
We did learn two more interesting things:
Even though both servers have two network connections, the network connection used for heartbeat/sync is “critical” for cluster operation. Breaking this connection causes an outage if freepbx-b is the active node (freepbx-a shoots it in the head), and the cluster would not self-recover if freepbx-a is in standby. This is what bit us last week.
Because we are using onboard IPMI for fencing/STONITH, our cluster probably won’t self-recover from the active node experiencing a power failure, as the active node’s IPMI device losing power makes the standby node think that it has fallen off the network. (This didn’t actually happen but Rob mentioned we should watch out for it.) I guess my team will need to look into other methods for fencing.